Dies ist eine HowTo-Anleitung:
Um SAP HANA Native Storage Extension (NSE) mit Partitionierung zu optimieren, müssen Sie einige Schlüsselstrategien berücksichtigen. Hier finden Sie eine detaillierte Erklärung, die auf die Verbesserung der Leistung und des Datenmanagements durch Partitionierung in Kombination mit NSE zugeschnitten ist:
| Strategie der Aufteilung | Verwenden Sie die Partitionierung, um große Tabellen in kleinere, besser zu verwaltende Segmente aufzuteilen. Dies kann auf der Grundlage von Bereichen (Bereichspartitionierung), Listenwerten (Listenpartitionierung) oder sogar Hash-Schlüsseln (Hash-Partitionierung) erfolgen. Die Partitionierung kann dabei helfen, die heißen und warmen Daten nach Zugriffsmustern auszurichten. So können beispielsweise Daten, auf die häufig zugegriffen wird, im Hauptspeicher aufbewahrt werden, während Daten, auf die weniger häufig zugegriffen wird, in NSE partitioniert werden können. vgl: https://help.sap.com/docs/SAP_HANA_PLATFORM/6b94445c94ae495c83a19646e7c3fd56/c3002bdbbb571014ac1ce966e91b1a38.html |
| Daten-Strukturierung | SAP HANA NSE ist für ein effektives Daten-Tiering konzipiert, das es ermöglicht, Daten, auf die weniger häufig zugegriffen wird, auf einem plattenbasierten Speicher zu speichern und so den Speicherbedarf und die Kosten zu reduzieren.Sie können Tiering auf Partitionsebene spezifizieren, wobei verschiedene Partitionen derselben Tabelle in verschiedenen Speicherschichten gespeichert werden können. Dieser Ansatz ist vorteilhaft für die Handhabung von Tabellen mit unterschiedlichen Datenzugriffsmustern in verschiedenen Segmenten. |
| Partitionsbeschneidung | Mit intelligenter Partitionierung ermöglichen Abfragen, die nur auf bestimmte Partitionen zugreifen, dass HANA ein Partition Pruning durchführt, bei dem nur relevante Partitionen gescannt werden. Dies reduziert die E/A- und Verarbeitungszeit erheblich, was insbesondere in Kombination mit NSE von Vorteil ist. Lade- und Entladevorgänge: Nutzen Sie die Möglichkeiten von NSE, um selten genutzte Partitionen manuell oder automatisch auf die Festplatte zu entladen und sie bei Bedarf wieder in den Speicher zu laden. Dieser Vorgang kann durch die Festlegung geeigneter Richtlinien auf der Grundlage von Nutzungsmustern und Geschäftsprioritäten optimiert werden. |
| Indizierung von Partitionen | Geeignete Indizierungsstrategien für Partitionen können die Zugriffsgeschwindigkeit weiter erhöhen. Während Indizes in HANA im Allgemeinen speicherresident sind, sollten Sie die Auswirkungen auf die Leistung berücksichtigen, wenn Indizes für NSE-Daten von der Festplatte geladen werden müssen. |
| Überwachung und Anpassungen | Die regelmäßige Überwachung der Leistungsmetriken sowohl für den Hauptspeicher als auch für die NSE ist von entscheidender Bedeutung. Anpassung der Partitionierungs- und Tiering-Strategien auf der Grundlage sich ändernder Zugriffsmuster und des Datenwachstums. |
| Kombination mit anderen Funktionen | Kombinieren Sie NSE mit Funktionen wie Delta Merges, LOB (Large Object)-Behandlung und Spaltenspeicherkomprimierung, um Leistung und Speicherplatz weiter zu optimieren. |
Dieses Beispiel beschreibt, wie man eine SAP HANA RANGE RANGE Partition für TABLE EDID4 erstellt und die Tabelle mit HANA NSE in den warmen Speicher entlädt:
# Identification of relevant tables - the enabled NSE Advisor helps you.
ALTER SYSTEM CLEAR CACHE ('cs_access_statistics');
ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini','system') SET ('cs_access_statistics','collection_enabled') = 'true' WITH RECONFIGURE;
# Verify the recommendations. A good idea is to collect some days of data:
SELECT * FROM SYS.M_CS_NSE_ADVISOR ;
# Range-Range Partitioning of table EDID4
ALTER TABLE EDID4
PARTITION BY RANGE (MANDT)(
PARTITION VALUE = '000',
PARTITION VALUE = '001',
PARTITION OTHERS ) ,
RANGE (DOCNUM)(
PARTITION '0000000000000000' <= VALUES < '0000000010000000',
PARTITION '0000000010000000' <= VALUES < '0000000020000000',
PARTITION '0000000020000000' <= VALUES < '0000000030000000',
PARTITION '0000000030000000' <= VALUES < '0000000040000000',
...
PARTITION '0000000018000000' <= VALUES < '0000000099999999',
PARTITION OTHERS ) ;
# Activate NSE for table EDID4
ALTER TABLE EDID4 PAGE LOADABLE;
# Unload EDID4
UNLOAD "EDID4" DELETE PERSISTENT MEMORY;
# The DELETE PERSISTENT MEMORY clause is optional and takes care that in context of persistent memory or the fast restart option (SAP Note 2700084) also the main storages are unloaded.
# Disable NSE Advisor if not required anymore
ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini','system') SET ('cs_access_statistics','collection_enabled') = 'false' WITH RECONFIGURE;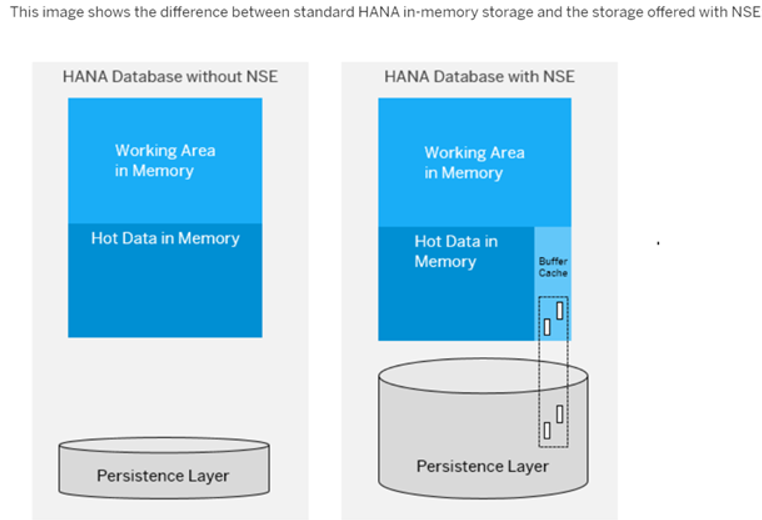
Überprüfung der Merge Operationen der Tabelle EDID4
select schema_name, table_name, part_id, raw_record_count_in_delta, last_merge_time, persistent_memory, read_count, write_count, merge_count from m_cs_tables where table_name = 'edid4' order by last_merge_time desc;
Die angegebene SQL-Abfrage hat zum Ziel, spezifische Informationen über die Tabelle EDID4 aus der Systemansicht m_cs_tables in einer SAP HANA Datenbank abzufragen. Hier ist die Bedeutung der einzelnen Komponenten der Abfrage:
schema_name: Gibt den Namen des Schemas an, in dem sich die Tabelle befindet.table_name: Der Name der Tabelle, für die die Informationen abgerufen werden, spezifiziert alsEDID4.part_id: Die ID der Partition der Tabelle, falls partitioniert.raw_record_count_in_delta: Die Anzahl der Rohdatensätze im Delta-Bereich der Tabelle. Dies gibt an, wie viele Einträge noch nicht in den Hauptdatenbereich (Main Store) übertragen wurden.last_merge_time: Der Zeitpunkt, zu dem die letzte Delta-Merge-Operation für diese Tabelle durchgeführt wurde. Delta-Merge ist ein Vorgang, bei dem Änderungen aus dem Delta-Bereich in den Hauptdatenbereich übertragen werden.PERSISTENT_MEMORY: Zeigt an, ob die Tabelle im persistenten Speicher (wie Intel Optane DC Persistent Memory) gespeichert wird.READ_COUNT: Die Anzahl der Leseoperationen, die auf der Tabelle ausgeführt wurden.WRITE_COUNT: Die Anzahl der Schreiboperationen, die auf der Tabelle ausgeführt wurden.MERGE_COUNT: Die Anzahl der Merge-Operationen, die auf der Tabelle ausgeführt wurden.
Die Abfrage sortiert die Ergebnisse in absteigender Reihenfolge nach dem Zeitpunkt des letzten Merges (last_merge_time desc), was bedeutet, dass die neuesten Merge-Operationen zuerst angezeigt werden. Dies kann hilfreich sein, um zu verstehen, wie aktuell die Daten in der Hauptdatenspeicher der Tabelle sind und wie oft und wann die Daten konsolidiert wurden.
Die Ergebnisse dieser Abfrage bieten wertvolle Einblicke in die Performance und das Verhalten der Tabelle EDID4 im Hinblick auf Speicheroperationen und Datenaktualität, was wichtig für die Optimierung und Überwachung der Datenbankperformance ist.
vgl. SAP HANA system view M_CS_TABLES: https://help.sap.com/docs/HANA_SERVICE_CF/7c78579ce9b14a669c1f3295b0d8ca16/20ad60f77519101498ccb610c33c3ca6.html?locale=en-US